

e75: Low profile, half-length PCIe Gen 4 board with a single Grayskull™ processor, our limited-availability entry-level board operating at 75W
e150: Standard height, 3/4 length PCIe Gen 4 board with one Grayskull™ processor, our solution for balancing power and throughput, operating at up to 200W

n150: Standard height, 3/4 length PCIe Gen 4 board with one Wormhole processor, our solution for balancing power and throughput, operating at up to 160W
n300: Standard height, 3/4 length PCIe Gen 4 board with dual Wormhole processors, operating at up to 300W

Powered by 32 Wormhole processors, the rack-mounted Galaxy 4U Server delivers dense, high-performance AI compute with full binary equivalency to our smaller systems

Our T-series workstations are turnkey solutions for running training and inference on our processors, from a single-user desktop workstation in the T1000 up to the T7000 rack-mounted system designed specifically to function as a host with our Galaxy 4U Server
Tenstorrent has two distinct software approaches:


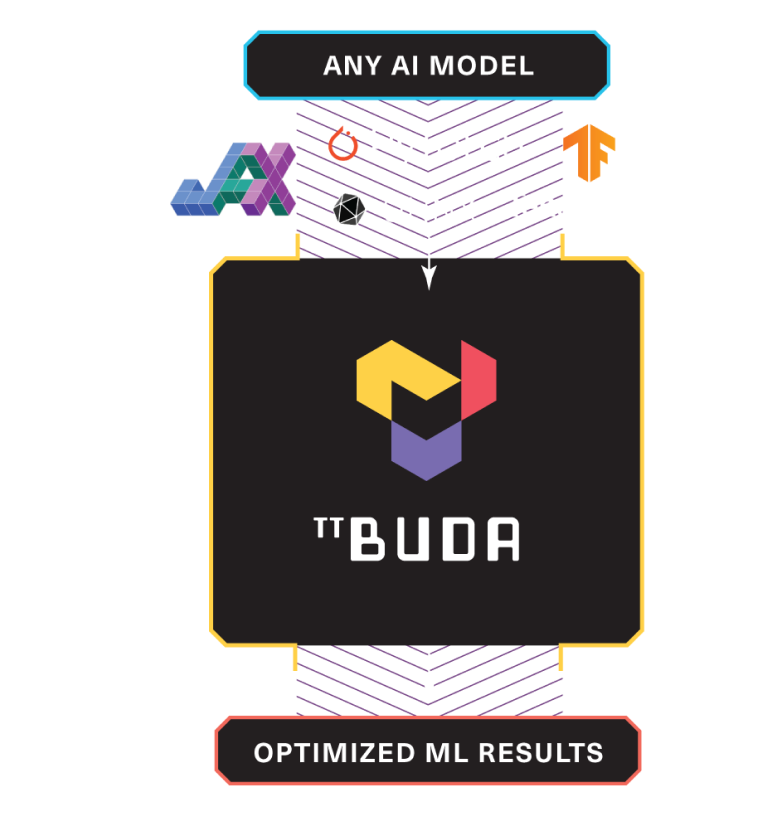
Great for production customers who want to get models up and running with ease. They want flexibility, but don’t have time to program new operations or contact support every time something changes.
-
Install TT-Buda™: Tools and anything you need to run a model
-
Run NLP model: A step-by-step tutorial for running BERT
-
Run Vision model: A step-by-step tutorial for running ResNet
-
Optimize Performance: Maximize BERT and ResNet's performance and throughput by feeding them with batched data
-
Deployment Ready: Deploy BERT and ResNet as an API using TorchServe


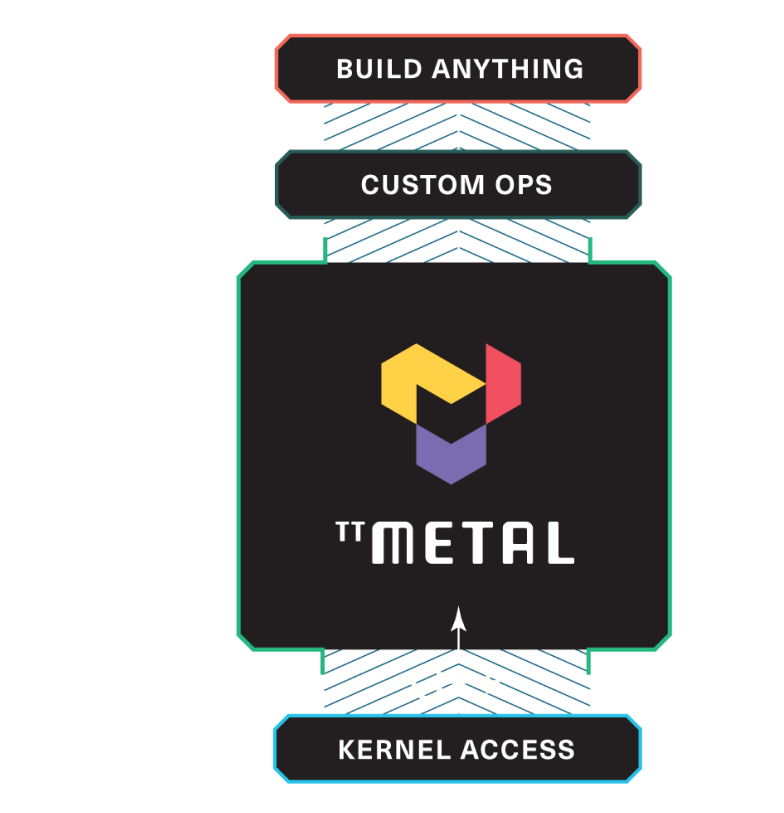
Great for development customers who want to customize their models, write new ones or even run non-machine learning code. No black boxes, encrypted APIs or hidden functions.
-
Install TT-Metalium: Download and install the necessary dependencies, pull the code from the TT-Metalium repo, and get it up and running as an executable
-
Run Models: Launch Falcon7B, followed by ResNet and BERT
-
TT-NN Basics: Set up a simple multi-head attention (MHA) operation from the Falcon 7B model
-
Optimize TT-NN: Boost the MHA operation with swift op-level enhancements
-
Understand TT-Metalium Kernel: Customize and optimize the matrix multiplication kernel essential for attention tasks